
01 - 1. 인공지능과 머신러닝, 딥러닝
인공지능이란
- 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
- 1943년 워런 매컬러와 월터 피츠가 최초로 뇌의 뉴런 개념을 발표함
- 1950년에는 앨런 튜링이 인공지능이 사람과 같은 지능을 가졌는지 테스트하는 유명한 튜링 테스트를 발표함
- 1956년에 발표한 다트머스 AI 컨퍼런스에서는 인공지능에 대한 전망이 최고조에 도달했는데 이 시기를 인공지능 태동기라고 함
- 1957년 프랑크 로젠블라트가 퍼셉트론을 발표, 1959년에는 데이비드 허블과 토르스텐 비셀이 고양이를 이용해 시각 피질이 있는 뉴런 기능을 연구함 -> 이를 통해 노벨상을 수상함 -> 이 시기를 인공지능 황금기
- 영화 속의 인공지능은 인공일반지능 또는 강인공지능이라고 불림
- 사람처럼 구분하기 어려운 지능을 가진 컴퓨터 시스템이 인공일반지능
- 우리가 현실에서 마주하고 있는 음성 비서, 자율 주행 자동차, 음악 추천, 기계 번역, 알파고 등이 약인공지능임
머신러닝이란
- 규칙을 일일이 프로그래밍 하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- 인공지능의 하위 분야 중에서 지능을 구현하기 위한 소프트웨어를 담당하는 핵심 분야
- 머신러닝은 통계학과 깊은 관련이 있음 -> 대표적으로 R언어
- R언어에는 다양한 머신러닝 알고리즘이 구현되어 있음
- 최근에는 수학 이론보다 경험을 바탕으로 발전 함 -> 컴퓨터 과학 분야의 대표적인 머신러닝 라이브러리인 사이킷런이 있음
딥러닝이란
- 인공 신경망을 기반으로 한 방법들을 통칭해서 딥러닝이라고 부름
- 사람들은 인공 신경망과 딥러닝을 크게 구분하지 않고 사용함
- 대표적으로는 텐서플로와 파이토치가 대표적인 라이브러리임
01-2. 코랩과 주피터 노트북
구글코랩
- 웹 브라우저에서 무료로 파이썬 프로그램을 테스트하고 저장할 수 있는 서비스
- 클라우드 기반의 주피터 노트북 환경 개발
- 구글 코랩을 이용하면 컴퓨터 성능과 상관없이 프로그램 실습 가능o
- 코랩은 웹 브라우저에서 텍스트와 프로그램 코드를 자유롭게 작성할 수 있는 온라인 에디터
- 이러한 코랩 파일을 노트북 또는 코랩 노트북 이라고 함
- 노트북에서의 셀은 코드 또는 텍스트 덩어리라고 보면 됨
텍스트 셀
- 셀은 코랩에서 실행 할 수 있는 최소 단위
- 셀 안에 있는 내용을 한 번에 실행하고 그 결과를 노트북에 나타냄
노트북
- 코랩의 데이터 작성 단위
- 일반 프로그램 파일과 달리 대화식으로 프로그램을 만들 수 있음
- 데이터 분석이나 교육에 매우 적합함
- 노트북에는 코드, 코드의 실행 결과, 문서를 모두 저장하여 보관가능
구글 드라이브
- 구글이 제공하는 클라우드 파일 저장 서비스
- 코랩에서 만든 노트북은 자동으로 구글 클라우드의 Colab Notebook 폴더에 저장됨
01-3. 마켓과 머신러닝
생선 분류 문제
한빛 마켓에서 파는 물건
도미, 곤돌매기, 농어, 강꼬치고기, 로치, 빙어, 송어
생선을 분류하기 위한 방법 1
-> 생선길이가 30cm 이상 = 도미
if fish_length >= 30:
print("도미")
but 30cm 보다 큰 생선이 무조건 도미 x
-> 그렇다면 어떻게 해야 하는가?
-> 머신러닝을 이용하여 스스로 기준을 찾아야 함
도미 데이터 준비하기
머신러닝으로 기준을 찾는 방법?
-> 여러 개의 도미 생선을 보면 스스로 어떤 생선이 도미인지를 구분할 기준을 찾음
이진분류
- 머신러닝에서 여러 개의 종류 중 하나를 구별해 내는 문제를 분류라고 함
- 2개의 클래스 중 하나를 고르는 문제를 이진 분류라고 함
방법 1. 코랩 메뉴에서 노트 생성
- 코랩 메뉴에서 [파일] - [새 노트]를 클릭
- 제목은 BreamAndsmelt 라고 수정함
첫번째 코드 창에 입력하기
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
- 리스트에서 첫번째 도미의 길이 = 25.4, 무게 = 242.0g
- 두번쨰 도미의 길이 = 26.3, 무게 = 290.0g
-> 이런 특징을 특성이라 부름
- 산점도는 길이를 x축, 무게를 y축으로 정하여 그래프에 그린것을 얘기함
- 맷플롯립은 파이썬에서 과학계산용 그래프를 그리는 대표적인 패키지
- import란 따로 만들어진 파이썬 패키지, (함수 묶음)을 차등하기 위해 불러오는 명령
두번째 코드 창에 입력하기
import matplotlib.pyplot as plt # matplotlib의 pylot 함수를 plt로 줄여서 사용
plt.scatter(bream_length, bream_weight)
plt.xlabel('length') # x축은 길이
plt.ylabel('weight') # y축은 무게
plt.show()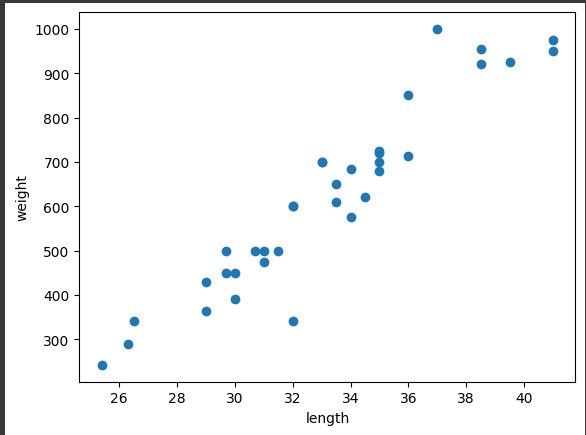
- 도미 35마리를 2차원 그래프에 점으로 나타냄
- x축은 길이, y축은 무게
- 2개의 특성을 사용해 그린 그래프이기 때문에 2차원 그래프라고 말함
- 산점도 그래프가 일직선에 가까운 형태로 나타내는 경우를 산정적이라고 함
빙어 데이터 준비하기
물류센터에 빙어가 많지 않아 준비한 빙어는 14마리!!
세번째 코드 창에 입력
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
다음으로 빙어 그래프도 그려보자
네번째 코드 창에 입력
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()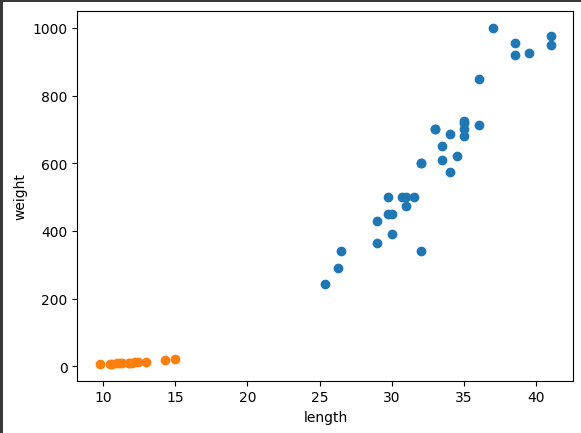
- 맷플롯립은 친절하게 2개의 산점도를 색깔로 구분해서 나타냄
- 주황색 점이 빙어의 산점도
- 빙어는 도미에 비해 길이도 무게도 매우 작다
첫번째 머신러닝 프로그램
K- 최근접 이웃 알고리즘
- 앞에서 준비했던 도미와 빙어 데이터를 하나로 합침
다섯번째 코드 창에 입력
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
- 참고로 이책에서 사용하는 머신러닝 패키지는 사이킷런
- 이 패키지를 사용하려면 각 특성의 리스트를 세로 방향으로 늘어뜨린 2차원 리스트를 만들어야 함
- 이렇게 만들기 위한 방법 2가지
- 파이썬의 zip() 함수, 리스트 내포구문을 사용
- zip() 함수는 나열된 리스트 각각에서 하나의 원소로 꺼내 반환
여섯번쨰 코드 창에 입력
fish_data = [[l,w] for l,w in zip(length, weight)]
- for문은 zip() 함수로 length와 weight 리스트에서 원소를 하나씩 꺼내어 l과 w에 할당
일곱번째 코드 창에 입력
print(fish_data)[[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0],
[29.7, 450.0], [29.7, 500.0], [30.0, 390.0], [30.0, 450.0], [30.7, 500.0],
[31.0, 475.0], [31.0, 500.0], [31.5, 500.0], [32.0, 340.0], [32.0, 600.0],
[32.0, 600.0], [33.0, 700.0], [33.0, 700.0], [33.5, 610.0], [33.5, 650.0]
[34.0, 575.0], [34.0, 685.0], [34.5, 620.0], [35.0, 680.0], [35.0, 700.0],
[35.0, 725.0], [35.0, 720.0], [36.0, 714.0], [36.0, 850.0], [37.0, 1000.0],
[38.5, 920.0], [38.5, 955.0], [39.5, 925.0], [41.0, 975.0], [41.0, 950.0],
[9.8, 6.7], [10.5, 7.5], [10.6, 7.0], [11.0, 9.7], [11.2, 9.8], [11.3, 8.7],
[11.8, 10.0], [11.8, 9.9], [12.0, 9.8], [12.2, 12.2], [12.4, 13.4],
[13.0, 12.2],[14.3, 19.7], [15.0, 19.9]]
- 첫번쨰 생선의 길이 25.4cm, 무게 242.0g
-> 하나의 리스트를 구분하고, 전체 리스트를 만듬 -> 2차원 리스트 혹은 리스트의 리스트라고 부름
- 마지막으로 준비할 데이터는 정답 데이터임
여덟번쨰 코드 입력
fish_target = [1]*35 + [0]*14
print(fish_target)[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- 이제 사이킷런 패키지에서 k-최근접 이웃 알고리즘을 구현한 클래스인 KNeighborsClassifier를 임포트함
아홉번쨰 코드 입력
rom sklearn.neighbors import KNeighborsClassifier
- 임포트한 KNeighborsClassifier 클래스의 객체를 먼저 만듬
kn = KNeighborsClassifier()
- 이 객체에 fish_data와 fish_target을 전달하여 도미를 찾기 위한 기준을 학습시킴
- 이를 훈련이라고 함
- 사이킷런에서는 fit() 매서드가 이런 역할을 함
kn.fit(fish_data, fish_target)
- fit 메서드는 주어진 데이터로 알고리즘을 훈련시킨 뒤 훈련합니다
머신러닝에서의 모델
- 머신러닝 알고리즘을 구현한 프로그램
- 알고리즘을(수식용으로) 구체화 하여 표현한 것
kn.score(fish_data, fish_target) -> 1.0
- 결과적으로 모든 fish_data의 답을 정확히 맞춤
- 이 값을 정확도라고 함
K- 최근접 이웃 알고리즘
- 어떤 데이터에 대한 답을 구할때 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용함
kn.predict([[30, 600]]) -> array([1])
- predict() 메서드는 새로운 데이터의 정답을 예측한다
- 이 메서드로 앞서 fit 메서드와 마찬가지로 리스트의 리스트를 전달해야 함
K- 최근접 이웃 알고리즘을 위해 해야할일
- 데이터를 모두 가지고 있는게 전부
- 새로운 데이터에 대해 예측할때 가장 가까운 직선거리에 어떤 데이터가 있는지 살피면 됨
단점
- 데이터가 아주 많은 경우 사용하기 x
- 데이터가 크기 때문에 메모리가 많이 필요하고, 직선거리를 계산하는데도 많은 시간이 필요함
KNeighborsClassifier 클래스
- _fit_x 속성에 전달한 fish_data
- -y 속성에 fish_target을 가지고 있음
print(kn._fit_x)[[ 25.4 242. ]
[ 26.3 290. ]
[ 26.5 340. ]
[ 29. 363. ]
[ 29. 430. ]
[ 29.7 450. ]
[ 29.7 500. ]
[ 30. 390. ]
[ 30. 450. ]
[ 30.7 500. ]
[ 31. 475. ]
[ 31. 500. ]
[ 31.5 500. ]
[ 32. 340. ]
[ 32. 600. ]
[ 32. 600. ]
[ 33. 700. ]
[ 33. 700. ]
[ 33.5 610. ]
[ 33.5 650. ]
[ 34. 575. ]
[ 34. 685. ]
[ 34.5 620. ]
[ 35. 680. ]
[ 35. 700. ]
[ 35. 725. ]
[ 35. 720. ]
[ 36. 714. ]
[ 36. 850. ]
[ 37. 1000. ]
[ 38.5 920. ]
[ 38.5 955. ]
[ 39.5 925. ]
[ 41. 975. ]
[ 41. 950. ]
[ 9.8 6.7]
[ 10.5 7.5]
[ 10.6 7. ]
[ 11. 9.7]
[ 11.2 9.8]
[ 11.3 8.7]
[ 11.8 10. ]
[ 11.8 9.9]
[ 12. 9.8]
[ 12.2 12.2]
[ 12.4 13.4]
[ 13. 12.2]
[ 14.3 19.7]
[ 15. 19.9]]
print(kn._y)[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0
0 0 0 0 0 0 0 0 0 0 0 0]
KNeighborsClassifier 클래스의 기본값 = 5
n= neighbors 매개변수로 바꿀 수 있음
kn49 = KNeighborsClassifier(n_neighbors=49)
- fish_data의 데이터 49개중 도미가 35개로 다수 차지 = 도미로 예측함
kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target)
정확도
- fish_data에 있는 생선 중에 도미가 35개이고 빙어가 14개임
- kn49 모델은 도미만 올바르게 맞춤
print(35/49) -> 0.7142857142857143
- 확실히 n_neighbors 매개변수를 새로 두는 것은 좋지 x
총 전체 소스 코드
""" ## 마켓과 머신러닝"""
""" ## 생선 분류 문제"""
"""### 도미 데이터 준비하기"""
ream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7,
31.0, 31.0, 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5,
33.5, 34.0, 34.0, 34.5, 35.0, 35.0, 35.0, 35.0, 36.0, 36.0, 37.0,
38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0,
450.0, 500.0, 475.0, 500.0, 500.0, 340.0, 600.0, 600.0, 700.0, 700.0,
610.0, 650.0, 575.0, 685.0, 620.0, 680.0, 700.0, 725.0, 720.0, 714.0,
850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
import matplotlib.pyplot as plt # matplotlib의 pylot 함수를 plt로 줄여서 사용
plt.scatter(bream_length, bream_weight)
plt.xlabel('length') # x축은 길이
plt.ylabel('weight') # y축은 무게
plt.show()
"""### 빙어 데이터 준비하기"""
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2,
12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4,
12.2, 19.7, 19.9]
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
"""## 첫 번째 머신러닝 프로그램"""
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
print(fish_data)
fish_target = [1]*35 + [0]*14
print(fish_target)
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target)
kn.score(fish_data, fish_target)
"""### k-최근접 이웃 알고리즘"""
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.scatter(30, 600, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
kn.predict([[30, 600]])
print(kn._fit_X)
print(kn._y)
kn49 = KNeighborsClassifier(n_neighbors=49)
kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target)
print(35/49)
'공부 기록일지' 카테고리의 다른 글
| 유성이의 공부일지(17-2) - 혼자공부하는 머신러닝 + 딥러닝 2장 (0) | 2024.09.21 |
|---|---|
| 유성이의 공부일지(17-1) - 혼자공부하는 머신러닝 + 딥러닝 2장 (1) | 2024.09.07 |
| 유성이의 공부일지(15) - 혼자공부하는 컴퓨터 구조 + 운영체제 15장 (0) | 2024.07.16 |
| 유성이의 공부일지(14) - 혼자공부하는 컴퓨터 구조 + 운영체제 14장 (0) | 2024.07.15 |
| 유성이의 공부일지(13) - 혼자공부하는 컴퓨터 구조 + 운영체제 13장 (0) | 2024.07.13 |